# AI Search using UI
## 1. Policy Fields
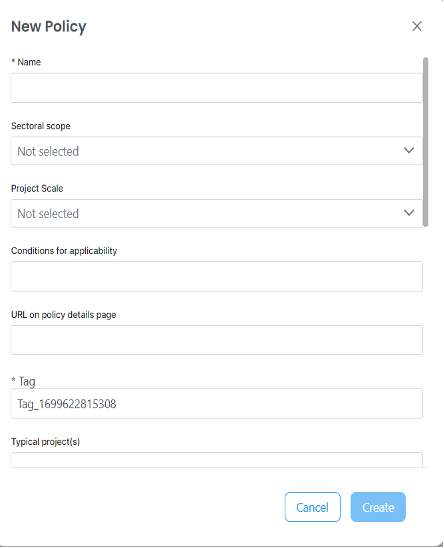
Several new fields have been incorporated into policy formulation to enhance AI search capabilities. These fields include:
1. Sectoral scope
2. Project Scale
3. Conditions for applicability
4. URL on policy details page
5. Typical projects, Description
6. Important parameters (at validation / monitored)
7. Applied Technology by Type
8. Mitigation Activity Type
9. Sub Type
## 2. .env file parameters
The .env file contains the following parameters:
| Parameter | Meaning |
| --------------------- | ---------------------------------------------------------- |
| OPENAI\_API\_KEY | OpenAI API Key |
| GPT\_VERSION | GPT version; by default, it is set to 'gpt-3.5-turbo' |
| VECTOR\_STORAGE\_PATH | The path where vector will be stored |
| DOCS\_STORAGE\_PATH | The path where generated methodology files will be stored. |
{% hint style="info" %}
These parameters are essential for configuring the AI Search tool.
{% endhint %}
## 3. Vector Construction
Vector construction is a pivotal process that involves compiling policy data and extracting descriptions from policy schemas. This process ensures the AI Search tool accurately interprets and utilizes policy-related information.
Every time a user publishes a policy, the vector is rebuilt through the following step-by-step process:
* Retrieving the required data from the newly added fields in the "create policy" modal window for each published policy from the database
* Retrieving the descriptions from the policy schemas and adding them to the resultant policy files. Descriptions containing fewer than 5 words are avoided to exclude unnecessary data for the language model.
* Creating separate files based on the fetched data, with each file containing the information describing one policy. Additionally, a file named metadata.txt is created, which contains shared data about all policies.
* Generating a new vector to replace the previous one.
Once the vector is ready, standard registry users can utilize the AI search feature to find the most suitable methodology:
Every response contains text and may include tiles with methodology data if the language model identifies relevant methodologies to suggest. Each tile comprises the policy name, a short description, and two links: as shown below: